[Uwaga] Techniczny post!
Czy da się łatwo zrobić swojego AI chat bota?
Jeżeli znasz się trochu na javascript (i/lub node.js) i wiesz nieco o serwerach, to tak!
Nie trzeba być turbo pythonowcem czy innym backendowcem, by to osiągnąć. Mówię z doświadczenia.
Ai chatbot który zna kontekst mojej firmy?
AI chat bot, który odpowiada na podstawie naszego kontekstu?
W sumie to marzenie wielu osób, żeby AI wiedział wszystko o naszej firmie i dostosował swoje odpowiedzi.
Co prawda Claude i ChatGPT już oferują możliwości dodawania kontekstu, ale potrzebujemy jeszcze, żeby ten bot był na naszej stronie dla klientów.
-
Co potrzeba by zrobić własnego AI bota?
Składniki:
1x Dostęp i klucz do OpenAI API lub Claude API
1x Piniondze, by zasilić konta
1x Apka lub stronka, gdzie można postawić tego bota
1x Ragie.ai
1x Serwer, który potrafi obsługiwać node serwery lub podobne (AWS, GCP, Azure...)
Sposób pieczenia:
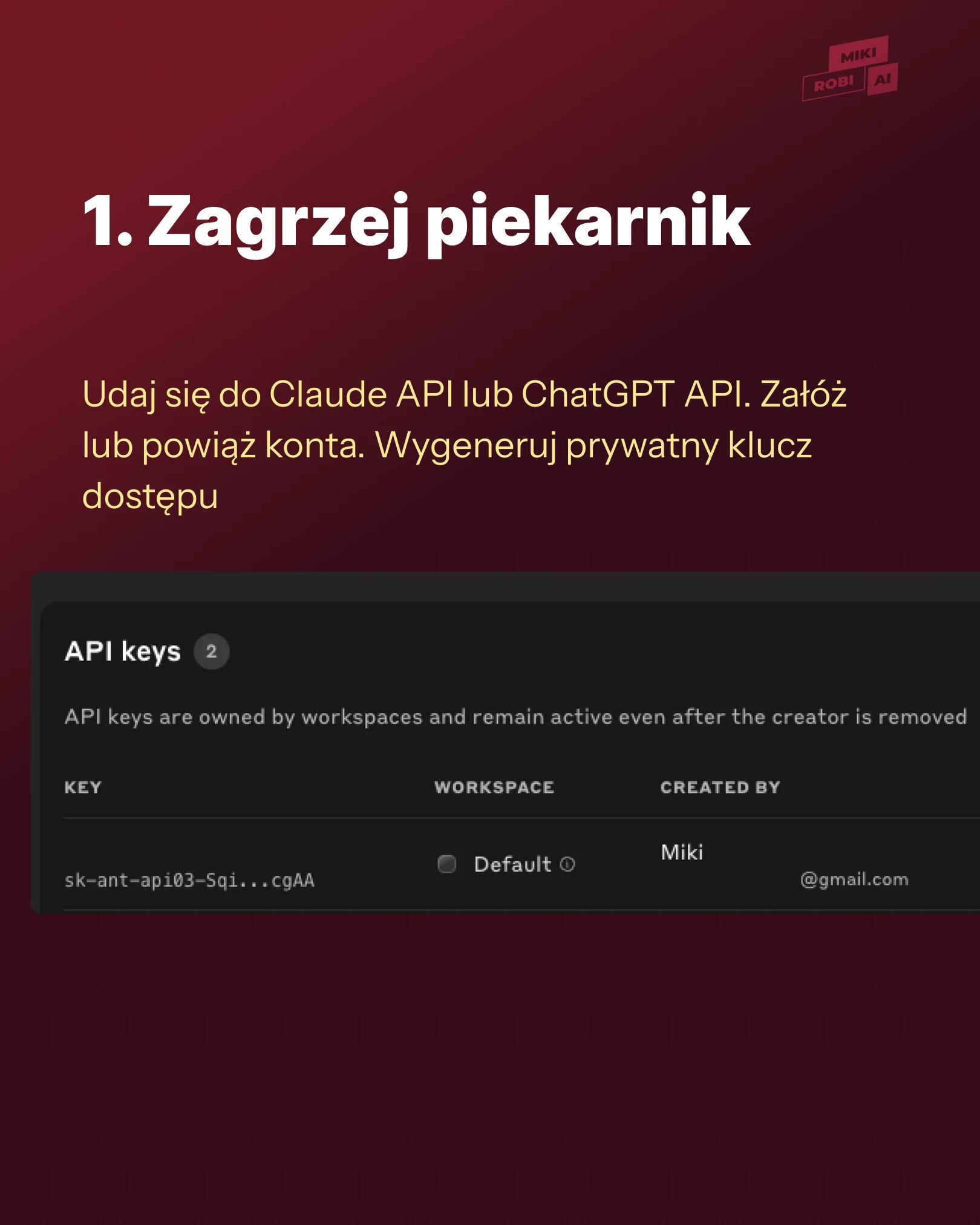
Zagrzej piekarnik — czyli udaj się do Claude API lub ChatGPT API.
Załóż lub powiąż konta. Wygeneruj prywatny klucz dostępu. Nie będę tutaj wnikać w szczegóły, należy podążać wg instrukcji lub wspomóc się AI chatem, żeby ten krok dokończyć. A jak już kiedyś wpinaliście się do API, to wiecie, o co chodzi.
Zobacz slajd numer 1.
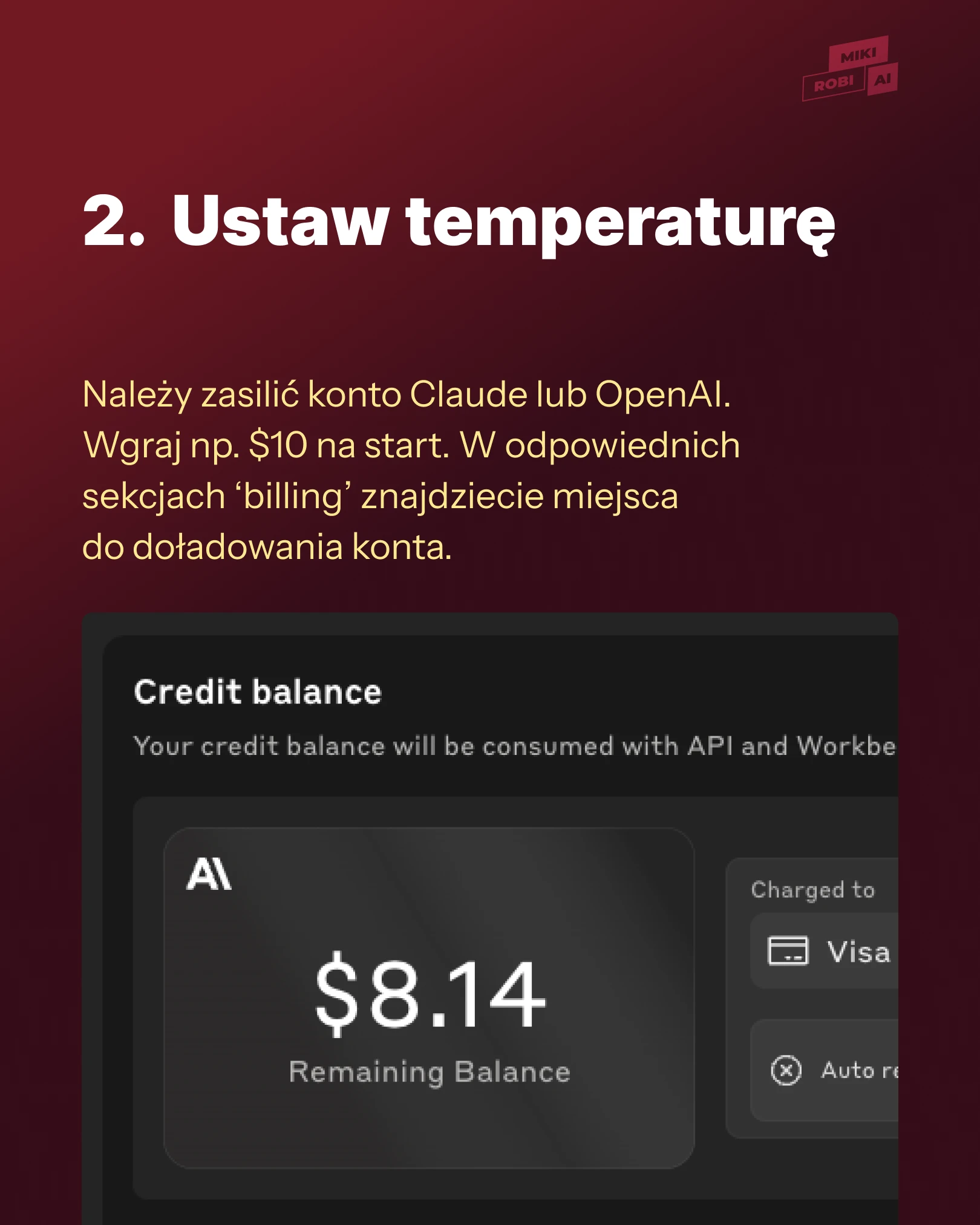
Ustaw temperaturę — o tym zapomniałem i dziwiłem się, czemu mi AI nie odpowiada.
Należy zasilić konto Claude lub OpenAI. Wgraj np. $10 na start.
W odpowiednich sekcjach 'billing' znajdziecie miejsca do doładowania konta. AI będzie zjadać kasę w zależności od użycia. Ja zrobiłem mój AI na podstawie Claude API, więc o nim będę mówić od teraz, ale to samo można zrobić w ChatGPT.
Zobacz slajd numer 2.
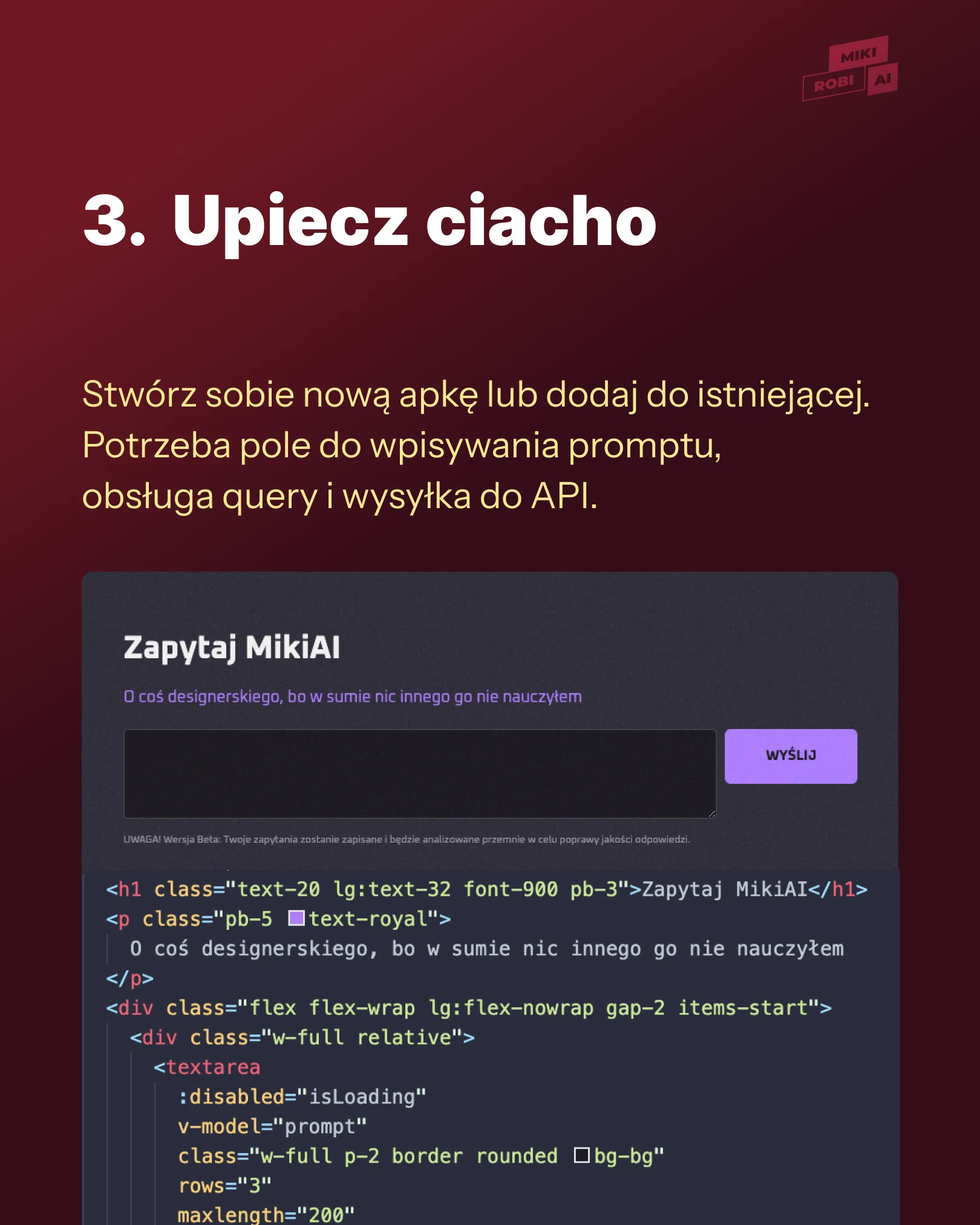
Upiecz ciacho — teraz trzeba się zabrać za apkę.
Tu również nie będę wchodzić w szczegóły. Stwórz sobie nową apkę lub dodaj do istniejącej (nieważne czy React, Vue czy Python, czy PHP), która obsłuży API.
Dodaj pole do wpisywania promptu, obsługa query i wysyłka do API. W dokumentacjach są przykłady jak się za to zabrać. Lub ;) poproście AI.
Apka musi wysłać POST do Claude API z całym promptem i kontekstem dla AI. I właśnie tutaj miałem pierwszy problem. Ja wysyłałem do Claude API cały mój wielki 80k tokenowy json z kontekstem dla AI. Bo bez tego nie odpowie mi sensownie.
Spalałem kasę jak szalony. 80k tokenów do AI, a on wracał z odpowiedzią 400 tokenów. Mocna dysproporcja.
Myślałem, że te AI'e są jakieś mądrzejsze. Że kontekst można mieć u Claude'a lub GPT. Ale z tego, co wiem, to tak to nie działa.
Zobacz slajd numer 3.
Udekoruj - Ragie.ai - tu wskakuje zbawca.
Ragie.ai to SaaS, który wstępnie filtruje twój kontekst. On zamienia mój json w chunki, czyli takie mini urywki wiedzy. W jakiś magiczny sposób (przy pomocy innego LLM i baz wektorowych) wyciąga segmenty mojego kontekstu, które mogą się przydać Claude'owi.
W ten sposób udało mi się obniżyć wejściowe tokeny do około 5k. Można ustawić, ile chunków ma przygotować Ragie. Trzeba znaleźć ten balans pomiędzy dobrym kontekstem i dobrą odpowiedzią a kosztem per prompt.
Zobacz slajd numer 4.
Wystaw i zjedz — ja akurat mam zwykły hosting, który nie odpala node skryptów, więc miałem dodatkowy problem do rozwiązania.
Akurat Cloudflare workers mi tu pomogły. Ale pewnie na waszych apkach są serwery w chmurze lub lepsza infrastruktura, więc wystarczy tylko odpalić apkę z chat botem na serwerze i zaczyna śmigać.
W pigułce:
Wysyłam pliki do Ragie.ai, one sobie wiszą u nich. Ragie.ai robi indeksację i filtrowanie informacji.
Moja apka najpierw wysyła prompt do API ragie, po czym dostaje kilka chunków kontekstu. Z tymi chunkami idę do drugiego API, czyli do Claude.
Wtedy on syntezuje odpowiedź w ładny sposób.
Na co zwracać uwagę jak tworzy się AI agent?
Warto mieć na uwadze:
W pakiecie darmowym w ragie dostajecie tylko 1000 odpytań. Potem trzeba przejść na dość drogą subskrypcję. Ale to już klienci za to zapłacą, prawda?
Skopiowałem przykład z Claude dokumentacji, który, jak się później okazało, ustawił najsilniejszego AI'a (Opus).
Każdy mój testowy prompt zjadał $2 z konta!!! WTF.
Dopiero jak zauważyłem to, zmieniłem na Sonneta, który zjada z 60% mniej, a ostatecznie zostawiłem go na najsłabszym AI (Haiku). Każdy prompt kosztuje kilka $ centów.
Jakość odpowiedzi nie jest turbo piękna, ale wystarczająca. Koszt zależy od tego, jaki model LLM-a użyjecie, ile kontekstu dajecie i o ile odpowiedzi zwrotnej poprosicie AI.
Zamiast korzystać z Ragie, dobry programista backendowy pewnie zdoła postawić taki LLM do filtracji kontekstu lokalnie na serwerze. Ponoć to nie aż takie skomplikowane i czasochłonne.
Ale chciałem pokazać, jak łatwo można postawić sobie infrastrukturę AI, korzystając z gotowców. Pewnie będzie ich coraz więcej i będą coraz lepsze.
Pisząc prompta do AI API, należy się zabezpieczyć. Ja się zabezpieczyłem tak, żeby zawsze odpowiadał po polsku, żeby nigdy nie przekraczał 1000 słów w odpowiedzi oraz żeby nie odpowiadał, jak coś wychodzi poza kontekst.
Czyli jak ktoś zapyta o historię USA zamiast czegoś o UI czy UX to AI ma grzecznie odpowiedzieć, że nie zna się i że nie odpowie.
Natomiast po jakimś czasie poluzowałem tę restrykcję. Teraz jak zapytasz o coś spoza kontekstu, to 1 zdanie na ten temat może syntezować, powiedzieć, że służy do odpowiedzi i UI i UX i żeby prompter udał się do wyszukiwarki, jak szuka innych informacji.
Ach i dodałem zabezpieczenie, że jak ktoś by brzydko promptował, wpisał coś sprośnego lub nieeleganckiego, to AI ma tylko odpisać "Ojej, z tym Ci nie pomogę" :D
Mam nadzieję że to pomoże, pa!